
Introduction: Rediscover the Expansion of the Universe With Python





Hubble's constant (equal to the rate of expansion of the universe) can be calculated with the help of Python, taking advantage of spectral and distance data collected from online databases. Once we've calculated Hubble's Constant, it's easy to extrapolate some other astronomically important values, such as the age of the universe and the size of the observable universe-- making this project a great introduction to the power of Python in Astronomy!
This was part of my group's final project for ASTRON 9: Introduction to Scientific Programming, taken at UC Berkeley in Summer 2023. We were asked to come up with an astro-themed Python project that took advantage of the skills we had learned in the first five weeks of the course.
Supplies
We'll use information from the following databases, which are free to access online.
- Sloan Digital Sky Survey (SDSS)'s SkyServer (for spectral data)
- NASA/IPAC Extragalactic Database (NED)'s Redshift-Independent Distances (NED-D) (for distance data)
We'll be working in a Python environment set up in Jupyter Notebook, with the numpy, matplotlib, scipy, pandas, and astropy libraries installed. For good measure, since we'll be using it, let's also define the speed of light, c.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.optimize import curve_fit
from astropy.io import fits
c = 299792 # speed of light in km/s
Step 1: Background


First, a bit of history:
In the 1910s, astronomer Vesto Slipher collected the first clear spectral data from distant galaxies. Almost all of the galaxies Slipher surveyed were redshifted (O’Raifeartaigh et al, 2014)– a result of the Doppler effect which occurs when an object emitting light is moving rapidly away from its observer. Slipher’s discovery added to a growing field of evidence that the universe is made up of many galaxies like our own, most of which are receding from us at great velocities– but the evidence was not yet conclusive.
In 1922, theoretical physicist Alexander Friedmann first seriously suggested that the universe itself might be expanding at a calculable rate. Friedmann derived a set of equations governing this hypothetical expansion from Einstein’s work in general relativity (Friedmann, 1922), but was careful not to outright endorse a theory of universe expansion: at the time, physicists including Albert Einstein generally believed that the universe was static (Einstein, 1917).
Five years later, astronomer and theoretical physicist Georges Lemaˆıtre independently concluded that the universe is expanding, also noting for the first time a proportional relationship between galaxies’ distances and velocities/redshifts (Lemaˆıtre, 1927). Lemaˆıtre determined the value of this proportionality constant– which he supposed corresponded to the rate at which the universe is expanding– to be 625 km/s/Mpc, though his results were not widely read outside of Belgium (Livio, 2011).
Two years later, astronomer Edwin Hubble independently observed the proportionality between galaxies’ distances and veloicities/redshifts. Using his own distance data and Slipher’s redshift data for 46 galaxies, Hubble plotted galactic velocity against distance, finding a linear relationship. Hubble took the slope of his linear fit, finding a proportionality constant of 500 km/s/Mpc (Hubble, 1929).
This relationship became known as Hubble’s law, and the proportionality constant (H0), Hubble’s constant.
v = (H0)(d)
Hubble’s law became widely accepted in the astronomical community as proof that the universe itself is expanding, including by Einstein, who abandoned his concept of a static universe (O’Raifeartaigh et al, 2014).
Interestingly, Hubble himself maintained for the rest of his life that this was a misinterpretation of his work, and that though galaxies were receding at great velocity, the universe itself was not actually expanding. However, had he lived past 1953, he might have been convinced otherwise: in the decades since, astronomers have fine-tuned Hubble’s constant with more and improved data and methodologies, honing it down to around 73 km/s/Mpc. Though to this day, there is ongoing discussion around the true value of Hubble's Constant, and whether it might even be dynamic!
Step 2: Overview of Project

Finding Hubble's Constant is pretty simple, in principle-- if we plot galaxies' recessional velocities (in kilometers per second) against their distances from us (in megaparsecs), the slope of a linear fit to that data (units: km/s/Mpc) should be equal to the rate at which the universe is expanding. Using this value, known as Hubble's Constant, we can also back-calculate the age of the universe, and do other cool things.
So how do we get this data? When Hubble calculated his constant, he used a combination of his own and Slipher's spectral data. Spectral (or spectroscopic) data reflects the presence of various electromagnetic wavelengths in the light emitted by an object, such as a star or a galaxy. Peaks in this data at certain wavelengths indicate the relative proportion of-- for example-- the chemical elements that make up an object.
In a phenomenon related to the Doppler Effect, the observed spectroscopic wavelengths of an object are shifted to the right if the object is moving away from the observer, and to the left if the object is moving towards the observer. When light behaves this way, it's known as redshift (if the object is moving away) or blueshift (if the object is moving closer). We can quantify redshift or blueshift by comparing the wavelengths of peaks in the spectra to their known wavelengths.
As with the Doppler Effect, the shift in an object's wavelength is linearly proportional to its recessional velocity-- armed with redshift data, we can calculate the speed at which an object (even a galaxy!) is moving away from us. So if we have spectral data, we can calculate redshift, and if we can calculate redshift, we can calculate velocity. That's one half of the information we need to plot velocity against distance.
When Hubble did his calculations, he used an innovative method for calculating the distance to galaxies, isolating single stars and measuring their distances using established methods, then using these values as stand-ins for the distances to the galaxies that contained them. We originally planned to perform our own distance analyses using related methods, but were short on time, and instead relied entirely on NED-D for redshift-independent galactic distance data.
Once we have both recessional velocities and distances for as few as a dozen galaxies, we have all we need to create a simple plot in Python, and perform our universe-scale calculations!
Step 3: Consolidate Data



To calculate galaxies’ redshifts, we need a database of spectroscopic data. To calculate galaxies’ recessional velocities (a function of redshift), we need a database of redshift-independent galaxy distance measurements.
As mentioned in the materials section, we found the very useful Sloan Digital Sky Survey to be a great source of raw spectral data, and NED-D's compilation of redshift-independent galaxy distances came in handy for our distance data. It's important that our distance values come from a database that include measured data, as opposed to calculated data; most calculations of galaxy distance take advantage of the distance-velocity formula we are trying to calculate here, and using such data would be circular.
There are many galaxies with available spectral data, and many galaxies with available distance data, but there are few databases for which both pieces of information are available for the same galaxies. We decided that the galaxies most likely to have available distance data (by far the rarer of the two types of data) are those that have been studied for the longest time, which we reasoned would be those that are the brightest in the night sky. Operating on this assumption, we performed a SQL search on SkyServer, returning only galaxies above a certain brightness and for which spectral data is available:
select top 100 p.objid, p.ra, p.dec, p.u, p.g, p.r, p.i, p.z, s.z as redshift, s.specobjid, s.plate, s.mjd, s.fiberid
from galaxy p, specobj s
where p.objid=s.bestobjid and p.g < 14
We saved this data to a csv, then hand-checked the first thirty galaxies that met these criteria against the NED-D database. Our assumption was that bright galaxies are well-studied galaxies, and that well-studied galaxies are more likely to have associated distance data. The assumption paid off: 25 of the 30 galaxies we checked had available distance data. Galaxy names, links to their SkyServer pages (which include download information for spectral data, with the FITS filetype), and distances were catalogued, again by hand, in a spreadsheet.

Step 4: Prepare Functions

This project requires only three functions:
- A modified Gaussian function (we add a continuum for fitting purposes), which we'll fit to prominent peaks in our spectral data in order to find the values of shifted wavelength peaks.
def gauss(x, A, mu, sigma, c): # defining the Gaussian function that we'll fit over the data
return (A * np.exp(-(x - mu)**2 / (2 * sigma**2))) + c # the Gaussian is modified with a "continuum", basically a constant we add to get to baseline
- A redshift function, whose inputs will be the observed and emitted wavelengths of those peaks.
- A recessional velocity function, whose only input will be redshift.
def get_redshift(lamo, lame): # writing the redshift function
return (lamo-lame)/lame # lamo = observed wavelength, lame = emitted wavelength
def recessional_velocity(z): # writing the recessional velocity function
v = z*c # z = redshift, c = speed of light
return v
Step 5: Load Spectral Data


Above, left: visualized spectral data from Sloan Digital Sky Survey (SDSS) for the galaxy NGC 99. Notice that emission peaks are labeled already; this will be helpful later! Above, right: Visualized FITS data for the NGC 99 galaxy, visualized using matplotlib.
The code that follows reads FITS data using the Astropy library, reveals the names of the columns available, and plots one (flux) against another (waves), giving us a spectroscopic plot in the common format.
from astropy.io import fits # this is the tool we'll use to analyze FITS data
hdul = fits.open('NGC99.fits') # hdul = Header Data Unit list
print(hdul[1].columns) # checking what the header data looks like
# now we can create lists from the data in the FITS file
spec = hdul[1].data['flux'] # let's call flux "spec(trum)"...
waves = 10**hdul[1].data['loglam'] # ...and loglam "waves" (raising everything to the power of 10)
fig = plt.figure() # create a new plot figure
fig.set_size_inches(25,10) # make the plot wider, to fit screen
plt.plot(waves, spec) # plot wavelengths and spectral output
plt.xlabel("wavelength, Angstroms")
plt.ylabel("flux")
....
Step 6: Trim Spectral Data Down to Single H-Alpha Peak

This process must be done manually for each galaxy's spectral data: in order to perform a Gaussian fit, we must first isolate the H-alpha peak. Modify the code below, so that x_min is just below the peak, and x_max is just above it; this may take a few tries.
The code that follows trims the imported spectral data to the specified range, then plots it for verification.
x_min = 6685
x_max = 6700
mask = (waves >= x_min) & (waves <= x_max)
waves2 = waves[mask]
spec2 = spec[mask]
fig = plt.figure() # create a new figure
fig.set_size_inches(25,10) # make it 25x10, like above
plt.plot(waves2, spec2) # plot the same thing, but in the next line, we'll crop it
plt.ylabel("flux")
Step 7: Perform Gaussian Fit

From here, it's pretty simple to apply our Gaussian fit. Like the spectral trimming step above, however, this will require some human input for each of the values; the initial "guesses" for our Gaussian curve!
Looking at the trimmed data from the previous step, for example, we can see that...
- The amplitude of our peak is around 70
- The approximate x-value of the local maximum is 6700
- The standard deviation is perhaps 1.5 (we don't have to be too precise on this one)
- The continuum, or lowest common y-value, is around 60
Entering these values in this order to our "initial_guess" list provides our Gaussian function from before with everything it needs to attempt a fit:
# Fit the Gaussian profile to the data
initial_guess = [70, 6700, 1.5, 60] # A, mu, sigma, c WE NEED TO ENTER OUR BEST ESTIMATES OF THESE VALUES!
fit_params, _ = curve_fit(gauss, waves2, spec2, p0=initial_guess)
...
# Print the fitted parameters
print("Fitted Parameters:")
print("Amplitude:", fit_params[0])
print("Mean:", fit_params[1])
print("Standard Deviation:", fit_params[2])
print("Continuum Level:", fit_params[3])
# Plot the original data and the fitted Gaussian
plt.plot(waves2, spec2, label="Spectral Data")
plt.plot(waves2, gauss(waves2, *fit_params), color='red', label="Fitted Gaussian")
plt.legend()
plt.xlabel("wavelength (Angstroms)")
plt.ylabel("flux")
plt.title("Fitting Gaussian to Spectrum")
Step 8: Calculate Redshift and Recessional Velocity
Now that we've fitted a curve to the data, we can use one of its outputs, the Gaussian mean (equivalent to the value of the peak wavelength) as one of the variables in our redshift function (observed wavelength, lamo). Since we decided in an earlier step that we're focusing solely on the prominent H-alpha peak, we already know that the other variable (the emitted wavelength, lamr) will be 6563 Angstrom.
With redshift z calculated and assigned a variable, we can now plug it into our recessional velocity formula, and receive an output v equivalent to the recessional velocity of the galaxy.
lamo = fit_params[1] # Gaussian mean # the emitted wavelength from this galaxy is the mean of the fitted function
lamr = 6563 # the original wavelength of this band is about 6563 angstrom
z = get_redshift(lamo, lamr)
v = recessional_velocity(z)
print("redshift:", z)
print("recessional velocity: ", v)
Step 9: Add Values to Dataframe and Repeat

Repeat steps 5-8 for each galaxy in the dataset we compiled in Step 3, each time adding redshift and recessional velocity values to the dataframe.
Step 10: Analyze Data


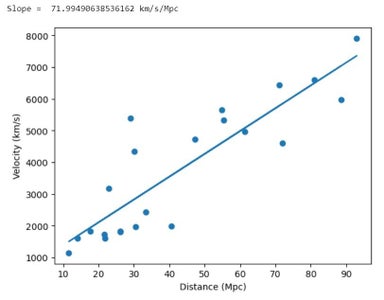
When the dataframe is complete (a minimum of 10 galaxies' worth of processed data is preferred), we can plot velocity over distance as a scatterplot with Pandas:
x = df['Distance (Mpc)'].to_numpy()
y = df['Velocity v (km/s)'].to_numpy()
plt.scatter(x,y)
plt.xlabel("Distance (Mpc)")
plt.ylabel("Velocity (km/s)")
Also perform a linear fit and print the slope, equal to Hubble's Constant:
a, b = np.polyfit(x, y, 1)
plt.plot(x, a*x+b)
print("Slope = ", a, "km/s/Mpc")
With just 25 galaxies' worth of data (the same number that Hubble used for his initial estimate), we've calculated a value for the rate of expansion of the universe: about 72 km/sec/Mpc. That's astonishingly well within the commonly agreed upon range of values, somewhere between 70 and 74 km/sec/Mpc.
Notice that Hubble's Constant can also be used to calculate the age of the universe by unit conversions:
#converting H0 from km/s/Mpc to 1/year
H0 = par[1]
H0_per_sec = H0 * 1/(3.086*10**19)
H0_per_yr = H0_per_sec * (3.1536*10**7)
age = (1/H0_per_yr)
age_billion = age/1e9
print(f'Estimated age of the universe: {age_billion:.2f} billion years')
Still using the same 25 galaxies' worth of data, we find that the age of the universe is approximately 13.47 billion years, which is once again astonishingly close to the generally accepted value of 13.787 billion years (although exciting recent JWST observations suggest that the universe may be about twice as old).
We can also attempt to determine the size of the observable universe:
#multiplying the speed of light to age of universe
new_age = 1/H0
observable_universe_size = new_age * c
print(observable_universe_size, 'mpc')
Using the same 25 galaxies' worth of data from above, we find that the radius of the observable universe is 4127.65 megaparsecs, or 1.35e10 light years. This is a bit further from the commonly accepted value of 4.7e10 light years, but still within an order of magnitude. Perhaps the difference can be attributed to factors we have not considered, such as dark energy or dark matter? A question for a future lab!







Comments